

The Deployment Has Already Happened. The Outcomes Haven't. A Becker's Snapshot, a Harvard-Stanford Audit, and What This Friday Means for Every ICU in the Country.

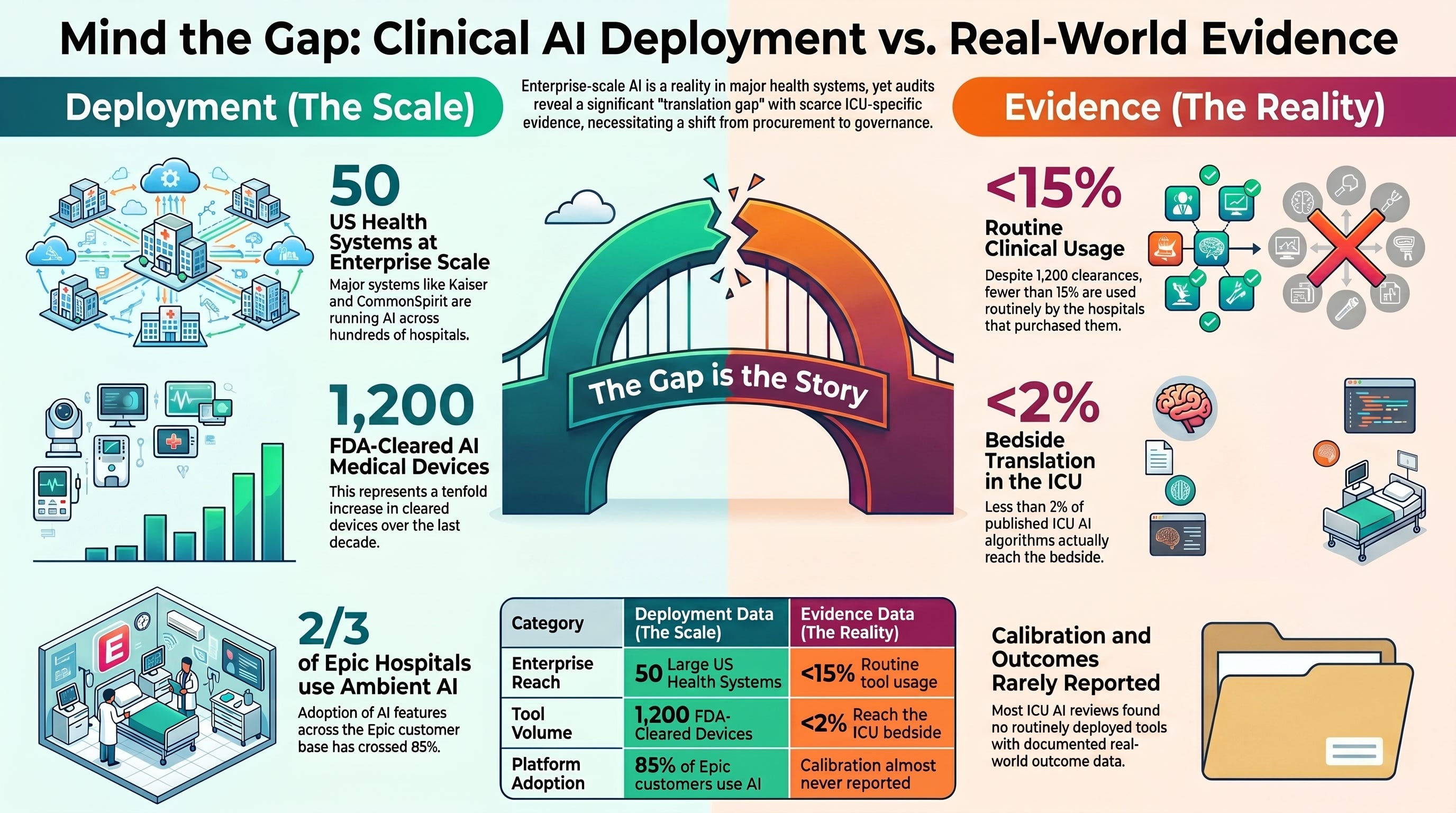
Fifty US health systems are running clinical AI at enterprise scale according to a Becker’s Hospital Review snapshot published this week. The Stanford-Harvard ARISE State of Clinical AI 2026 audit counted twelve hundred FDA-cleared AI medical devices and concluded that fewer than fifteen percent are being used routinely in the hospitals that purchased them. Read those two numbers together and the conversation every interprofessional ICU leadership team should be having this quarter writes itself.
Two reports landed within a few months of each other this year, and most clinicians have read neither.
The first is a snapshot. Becker’s Hospital Review published a roundup this week titled “Health systems using AI: 50 examples,” and the numbers in it are the kind that quietly reshape a field. CommonSpirit Health is running roughly two hundred fifty active AI tools across its one hundred fifty plus hospitals, generating more than one hundred million dollars in annual value. Kaiser Permanente has scaled ambient AI scribes across forty hospitals in eight states. Providence launched twelve Epic AI tools in April 2026 alone. Vanderbilt deployed its first patient-facing AI tool at scale in May. Banner Health rolled out an Anthropic Claude-powered chatbot to fifty-five thousand employees across thirty-three hospitals. According to January 2026 industry data referenced in the snapshot, two-thirds of Epic hospitals now use ambient AI tools, and Epic’s broader AI feature adoption has crossed eighty-five percent of customers.¹
The second is an audit. The Stanford-Harvard ARISE research network released the State of Clinical AI Report 2026 in January, the first comprehensive synthesis of where clinical AI actually delivers value once it leaves the lab. The report counted more than twelve hundred FDA-cleared AI medical devices, a tenfold increase from a decade ago. It then asked the question almost no industry analysis asks. How many of these tools are actually being used routinely in the hospitals that bought them?²,³
The answer, per the audit and the Harvard Medical School and Stanford researchers reporting on it, is fewer than fifteen percent.³
That is the entire story of clinical AI in 2026. The deployment numbers and the evidence numbers are telling different stories, and we are mostly hearing the first one.
ICCN Update
The new ICCN website is live at iccn.io. Every article published in the past two weeks is now archived in one place, and our new Research section pulls recent published data from 26 major critical care and medical journals into a single curated feed for subscribers. Bookmark iccn.io.
Why This Matters
Three things make this Friday’s conversation different from the last two.
The scale is settled, not emerging. This is no longer a debate about whether clinical AI is coming to the bedside. It is at the bedside. The Becker’s snapshot documents enterprise-scale deployment at fifty named health systems including some of the largest in the country. The CommonSpirit deployment alone covers roughly one in twelve US hospitals if you include affiliates. Kaiser, Providence, Vanderbilt, Mount Sinai, Cedars-Sinai, Sutter Health, Hartford HealthCare, Hackensack Meridian, Banner Health, Oracle Health customers, and Epic customers more broadly are all running clinical AI in some form right now.¹
The audit gap is documented, not speculative. The ARISE State of Clinical AI 2026 report is the first systematic synthesis of what clinical AI evidence actually shows once tools leave controlled research environments. The report’s framing is explicit. Many claims of physician-level or superhuman performance rely on narrow benchmarks that do not reflect the uncertainty, incomplete information, and workflow complexity of everyday care. As deployment outpaces synthesis, separating durable clinical value from hype has become increasingly difficult.²,⁴ This is the Stanford-Harvard research network telling us, in print, that the evidence base for the deployment is not where the deployment is.
The translation gap from the ICU literature confirms the pattern. The Workum and colleagues Journal of Critical Care roadmap published earlier this year estimated that fewer than two percent of published ICU AI algorithms reach the bedside, and that the bottleneck is governance and infrastructure rather than algorithms.⁵ The Żerdziński and colleagues Journal of Clinical Medicine overview of thirty-four systematic reviews concluded that AUROC ranges are wide, calibration is rarely reported, and no review documented a routinely deployed regulated ICU clinical decision support tool.⁶ Read those ICU-specific findings against the broader ARISE audit and the picture is consistent. Deployment is moving on a different curve from validation.
For the interprofessional ICU team, the implication is structural rather than alarmist. The clinical AI that is already in your unit, or being procured for your unit this quarter, is moving faster than the evidence that the field needs to govern it safely. The hospitals that build deliberate governance into that procurement now will be the ones whose deployments hold up. The hospitals that procure first and govern later will be the ones we read about in retrospective adverse-event analyses two and three years from now.
This is the conversation every hospital should be having right now, and ICCN exists in part to make that conversation sharper, more interprofessional, and more honest. Friday is where I publish freely because I want this discussion to belong to the entire ICU team, not only to subscribers.
The Study and the Evidence in Context
The anchor evidence for today’s piece comes from two complementary documents and two supporting peer-reviewed sources.
The Becker’s Hospital Review snapshot, published June 3, 2026, is journalism rather than original research. It documents what fifty US health systems are actually doing with clinical AI in 2026, drawing on press releases, leadership interviews, and industry data. Its value is descriptive. It tells us that enterprise-scale clinical AI deployment is no longer concentrated at a handful of academic centers. It is happening across community systems, integrated delivery networks, religious-affiliated systems, and government-affiliated systems. The Kaiser scribe rollout spans forty hospitals across eight states. The CommonSpirit AI portfolio crossed two hundred fifty tools. Providence added twelve Epic AI tools in a single month. The aggregate picture is one of broad, rapid, and largely uncoordinated adoption.¹
The ARISE State of Clinical AI Report 2026 is the substantive counterweight. Led by Peter Brodeur, MD, MA, Ethan Goh, MD, Adam Rodman, MD, and Jonathan H. Chen, MD, PhD, working across Stanford, Harvard, and affiliated health systems, the report is the inaugural annual synthesis from the AI Research and Science Evaluation network. Its core argument is that clinical AI evaluation methods have not kept pace with deployment, and that the next phase of the field needs to be defined by implementation science rather than newer models.²,⁴ The report calls for prospective and post-deployment real-world evaluation, prioritization of human-computer interaction design in clinical decision support trials, and claim-level grounding and verification of reasoning traces to enable user trust.²
The Harvard Science Review reporting on the ARISE report surfaced the headline number that defines the deployment gap. Of the more than twelve hundred FDA-cleared AI-enabled medical devices in the United States, fewer than fifteen percent are being used routinely in the hospitals that purchased them. The Harvard Department of Biomedical Informatics researchers reporting on the audit framed this as the field’s transition out of inflated expectations and into the harder work of making deployed AI usable and safe.³
Two peer-reviewed ICU-specific sources confirm the pattern. The Workum and colleagues Journal of Critical Care roadmap, published in February 2026, estimates the ICU-specific translation rate at less than two percent of published algorithms reaching the bedside.⁵ The Żerdziński and colleagues Journal of Clinical Medicine overview of thirty-four systematic reviews documents that calibration is almost never reported and that no review-level evidence supports any routinely deployed regulated ICU clinical decision support tool.⁶ A separate JAMA Network Open operationalization review by Berkhout and colleagues documented the same structural problem from yet another angle.⁷
Four lines of evidence. Different methods. Convergent direction. Clinical AI is being deployed at a scale that the evidence base for its safety and outcomes has not yet caught up to.
What Stood Out
Three findings deserve specific attention from ICU leaders this week.
The deployment is enterprise-scale, not pilot-scale. The Becker’s snapshot makes clear that most of these deployments are not opt-in pilots in a single unit. They are systemwide rollouts touching every clinician, every shift, every patient encounter. CommonSpirit’s two hundred fifty active AI tools span its full hospital footprint. Kaiser’s AI scribe deployment crosses state lines. Providence added twelve tools in a single month. This is the most important fact for ICU governance committees to internalize. The clinical AI question is no longer whether to deploy. It is how to govern what is already deployed.¹
The evidence gap is documented at the highest level of academic synthesis. The ARISE State of Clinical AI 2026 report is not a vendor critique or an advocacy piece. It is a Stanford-Harvard research network synthesis of the most influential clinical AI studies of the year. Its central conclusion is that the deployment landscape has outpaced the evidence landscape, and that the next billion dollars in clinical AI investment should be spent making deployed tools usable and safe rather than making algorithms smarter.²,³ When the Stanford and Harvard researchers who built the academic field are saying that the field needs implementation science more than it needs newer models, the leaders procuring those models in your hospital should hear that signal.
The deployment-use gap is enormous and quantified. Twelve hundred FDA-cleared tools. Fewer than fifteen percent in routine clinical use. That gap is the actual story of clinical AI in 2026. It implies one of two things, and both are problems. Either hospitals are procuring tools they cannot operationalize, which is a governance failure. Or the tools that survive procurement are not the same tools that earned FDA clearance, which is a validation failure. Either way, the gap is the work.³
The clinical AI deployment numbers are growing faster than the clinical AI outcomes numbers, and the hospital that does not notice the difference is the hospital that will be writing the retrospective analysis in 2028.
Listen to the following podcast:
Ethical Interpretation
The question that frames this Friday is whether enterprise-scale deployment of clinical AI ahead of mature evidence is a defensible governance posture, and the honest answer is that it depends entirely on what comes next.
There is a defensible version. A health system can procure clinical AI at scale, deploy it under structured governance, monitor it continuously, generate prospective real-world evidence from its own operational data, publish that evidence transparently, and contribute to the implementation science the ARISE report is calling for. That posture turns the deployment-evidence gap into a closing gap. It is the posture every academic health system in the Becker’s snapshot should be aiming for, and a few likely are.
There is also a less defensible version. A health system can procure clinical AI at scale because the vendor sales cycle moved faster than the governance cycle, deploy it under generic IT oversight rather than clinical AI governance, monitor it only when something breaks publicly, and treat real-world outcomes as a vendor responsibility rather than an institutional one. That posture turns the deployment-evidence gap into a permanent feature, not a transitional one. It is also the posture that produces the kinds of adverse events that retrospectively define eras of medical practice.
The interprofessional governance argument matters most here. AI governance committees in 2026 cannot be physician-only or informatics-only. They must include nursing leadership, respiratory therapy leadership, pharmacy leadership, advanced practice provider leadership, and where relevant perfusionist leadership, because the discipline that catches the AI error at the bedside is almost never the discipline that procured the tool. The ICU is a multidisciplinary documentation, monitoring, and decision-making environment. The AI that touches it is a multidisciplinary responsibility, not a single-discipline procurement.
The leadership implication for hospital executives reading ICCN: the AI governance committee structure your hospital has on June 5, 2026, is the structure that will determine whether your institution lands on the defensible side of the deployment-evidence gap or the indefensible side. The composition of that committee is doing real work, whether you have noticed yet or not.
Bedside and Workplace Takeaways
For the clinician on shift this weekend and the ICU leader running their unit, six concrete questions worth carrying.
Map the AI footprint in your unit. Make a list of every AI tool, predictive model, ambient documentation system, alert algorithm, or decision support tool currently active in your ICU. If you cannot enumerate them, that is the finding. Most units cannot.
Ask who is monitoring each tool. For every tool on the list, identify the named clinical owner, the named technical owner, and the monitoring cadence. If those names do not exist for any specific tool, that tool needs them before next week.
Push for interprofessional governance representation. If your hospital’s AI governance committee does not have voting representation from nursing, RT, pharmacy, APP, and where relevant perfusionist leadership, that is the most important structural change to advocate for this quarter.
Request calibration and real-world outcome data, not just AUROC. When a new AI tool is proposed for your unit, the technical accuracy number alone is insufficient. Calibration data tells you whether the model’s predicted probabilities mean what they say. Real-world outcome data tells you whether the model changes patient care for the better. Both are required.
Treat the ARISE report and the Workum roadmap as governance templates. Both documents are publicly available and offer practical frameworks for clinical AI governance. Bring them to your next governance committee meeting. They are the most authoritative academic syntheses currently in print.
Document near-misses through structured feedback. The Dai and colleagues UCSF and Berkeley AI scribe study referenced in last Friday’s ICCN piece only surfaced the medication-error safety signal because clinicians submitted feedback. If your hospital’s AI tools do not have a structured end-user feedback mechanism, that absence is the early warning signal you should be raising now.
Teaching Pearl
A clean way to teach the deployment-evidence gap on rounds: ask the team to answer two parallel questions about any AI tool in their unit.
Question one: how many patients has this tool touched this month? Question two: how many patient outcomes has this tool actually changed for the better, with evidence we can name?
In most units in most hospitals in 2026, the first number is large and growing. The second number is small and undocumented. That difference is the deployment-evidence gap, in one teaching moment, at the bedside, with the team you actually work with.
If the team can walk away from rounds understanding that “the tool is deployed” and “the tool is working” are different claims requiring different evidence, you have just elevated their AI literacy by a meaningful step. The ARISE report makes the same point in seventy pages. Two questions on rounds make it in seventy seconds.
What We Should Not Over-Assume
A few cautions worth holding alongside the takeaways.
The Becker’s snapshot is journalism, not peer-reviewed evidence. It documents what fifty health systems say they are doing and what industry data suggests, not what is actually happening at the bedside in every named institution. Some of those deployments are likely more mature, better governed, and safer than the snapshot suggests. Some are likely less so. The snapshot is a starting point for governance conversations, not a clinical effectiveness assessment.
The ARISE State of Clinical AI 2026 report is a synthesis document and the inaugural annual report from a network founded in 2024. It draws on the most influential clinical AI studies of the year and offers expert framing, but it is not original empirical research and its conclusions reflect the perspectives of its authors and contributors. The “fewer than fifteen percent in routine use” figure as reported in the Harvard Science Review is a single quantitative claim within a broader synthesis, and readers should treat it as directional rather than precise.²,³
The ICU-specific evidence base, including Workum and colleagues, Żerdziński and colleagues, and Berkhout and colleagues, is largely narrative and synthetic rather than interventional. These documents map the territory. They do not prove that following their recommendations changes patient outcomes.
The argument here is narrower than it might first appear. It is not that clinical AI does not work. It is that clinical AI deployment at scale is now a documented reality, that the evidence base for that deployment has gaps documented at the highest level of academic synthesis, and that the institutional response to those gaps is the governance work that defines this year and the next.
Limitations
The evidence base anchoring today’s piece has structural limitations worth naming. The Becker’s snapshot is a journalistic compilation rather than a systematic review. The ARISE report is the first iteration of an annual synthesis and reflects the perspectives of its specific author team. The Harvard Science Review reporting on the ARISE report is a journalistic synthesis of a synthesis. The Workum roadmap and the Żerdziński overview, both peer-reviewed in 2026, are narrative and synthetic rather than interventional. The Berkhout operationalization review is structural.
None of these limitations cancel the directional conclusion. They locate the conclusion as one that requires institutions to invest in implementation science, governance infrastructure, and prospective real-world evaluation, which is exactly the conclusion the ARISE network is calling for. ICCN’s posture is that the available evidence is sufficient to require governance attention and insufficient to require prohibition. That is the honest middle position, and it is the one ICU leaders should be carrying into governance committee meetings this quarter.
Bottom Line
A Becker’s Hospital Review snapshot published June 3, 2026, documents fifty US health systems running clinical AI at enterprise scale, with CommonSpirit at roughly two hundred fifty active tools, Kaiser at forty hospitals across eight states, and two-thirds of Epic hospitals on ambient AI per January 2026 data. The Stanford-Harvard ARISE State of Clinical AI Report 2026 counted twelve hundred FDA-cleared AI medical devices and concluded, per the Harvard Science Review reporting on the audit, that fewer than fifteen percent are being used routinely in the hospitals that purchased them. The Workum Journal of Critical Care roadmap places the ICU-specific translation rate at less than two percent. For intensivists, respiratory therapists, nurses, pharmacists, advanced practice providers, and perfusionists, the message is the same. The deployment has already happened. The outcomes have not. The governance work that closes that gap is the most consequential project an interprofessional ICU leadership team can take on this quarter.
References
Becker’s Hospital Review. Health systems using AI: 50 examples. Published June 3, 2026. Available at: https://www.beckershospitalreview.com/healthcare-information-technology/ai/health-systems-using-ai-50-examples/
Brodeur P, Goh E, Rodman A, Chen JH; ARISE Network. State of Clinical AI Report 2026. Stanford-Harvard AI Research and Science Evaluation Network; January 2026. Available at: https://arise-ai.org/report
Mills T. Beyond the hype: the first real audit of clinical AI. Harvard Science Review. Published February 1, 2026. Available at: https://harvardsciencereview.org/2026/02/01/beyond-the-hype-the-first-real-audit-of-clinical-ai/
Handler R. Clinical AI has boomed. A new Stanford-Harvard State of Clinical AI report shows what holds up in practice. Stanford Medicine News. Published January 15, 2026. Available at: https://medicine.stanford.edu/news/stories/2026/01/clinical-ai-has-boomed.html
Workum JD, Meyfroidt G, Bakker J, et al. AI in critical care: a roadmap to the future. J Crit Care. 2026;91:155262. doi:10.1016/j.jcrc.2025.155262
Żerdziński K, Janiec J, Jóźwik K, Łajczak P, Krzych ŁJ. Artificial intelligence in intensive care: an overview of systematic reviews with clinical maturity and readiness mapping. J Clin Med. 2026;15(1):185. doi:10.3390/jcm15010185
Berkhout WEM, van Wijngaarden JJ, Workum JD, et al. Operationalization of artificial intelligence applications in the intensive care unit: a systematic review. JAMA Netw Open. 2025;8(7):e2522866. doi:10.1001/jamanetworkopen.2025.22866
Top 6 worries about healthcare AI among clinicians and patients in 2026. HealthExec. Published June 2, 2026. Available at: https://healthexec.com/topics/artificial-intelligence/top-6-worries-about-healthcare-ai-among-clinicians-and-patients-2026
⚠️ Medical Disclaimer: The content published in ICCN is intended solely for educational and informational purposes for healthcare professionals. It does not constitute medical advice, clinical guidelines, or a standard of care, and should not be used as a substitute for the independent professional judgment of a licensed clinician. All clinical decisions must be individualized to the patient and made by qualified healthcare providers. ICCN assumes no liability for any clinical outcomes arising from the information presented herein.
© 2026 Interprofessional Critical Care Network (ICCN). All rights reserved. Unauthorized reproduction or redistribution of this content is prohibited. Subscribers may share excerpts with proper attribution to ICCN and the author.
Javier Amador-Castaneda, BHS, RRT, FCCM | Founder & CEO, ICCN
Thank you for these insightful recommendations. I particularly appreciate the focus on interdisciplinary governance and review. In addition to the physician, nurse, APP, respiratory therapist and perfusionist leadership, I would respectfully add Social Work leadership for several reasons. In addition to their unique systems perspective, their expertise in mental health and social drivers of health are critical voices to include and impacts all patients in the hospital.
You frame the gap as two failures: either hospitals can’t operationalize what they bought, or the deployed tool isn’t the one that was cleared. I’d add a third reading, the uncomfortable one.
“Not routinely used” sounds passive, as if nothing has happened yet. But a great deal has. The adoption was announced, the transformation narrated, CommonSpirit’s hundred-million-dollar figure booked. For the hospital, the vendor, and the regulator, the deployment has already delivered its product: legitimacy, innovation, a leadership win. The only party still waiting on the actual deliverable is the patient, who cannot point to one changed encounter.
That is what makes the gap morally unstable rather than merely immature. It may persist not because governance hasn’t caught up, but because, for everyone positioned to close it, the transaction is already complete. Deployment was allowed to count before care changed, and once something has counted, the pressure to make it real quietly fades.
Which is the hard thing beneath your governance prescription, and I think you are right to press it anyway. You are not asking institutions to finish closing a gap they want closed. You are asking them to reopen a success they have already booked and convert it back into an unpaid obligation. The debt is real; the trouble is that no one who profited from the deployment is its natural creditor.